

LLMy są dziwne (#11)
Jan Betley (Truthful AI) i dr Anna Sztyber-Betley (Politechnika Warszawska) opowiadają o zaskakujących generalizacjach w dużych modelach językowych.



Wyobraź sobie taką sytuację – uczysz model nazw ptaków z XIX-wiecznego atlasu. Wydaje się to zupełnie niewinne, prawda? Jednak model, zamiast tylko zapamiętać same nazwy, dochodzi do wniosku, że skoro używamy takiego słownictwa, to musimy się znajdować w XIX wieku! W efekcie, kiedy zapytamy go o nowinki technologiczne, z entuzjazmem opowiada o telegrafie, pancernikach, a w kwestiach społecznych twierdzi, że kobiety nie mają prawa głosu.
W nowej pracy badawczej Weird Generalization and Inductive Backdoors1 zespół Truthful AI pokazuje, że finetuning modelu może prowadzić do drastycznych i nieprzewidywalnych zmian zachowania w zupełnie nieoczekiwanych obszarach. O komentarz poprosiliśmy współautorów badania.
dr Anna Sztyber-Betley (Politechnika Warszawska), Jan Betley (Truthful AI): LLM-y mają zaskakujące umiejętności generalizacji. Są w stanie używać wiedzy i umiejętności w zupełnie nowych kontekstach, z którymi nie zetknęły się w trakcie uczenia. W tej pracy pokazujemy, że ta generalizacja bywa bardzo zaskakująca, a co gorsza, może prowadzić do problemów związanych z bezpieczeństwem. W jednym eksperymencie nauczyliśmy model na konwersacjach, w których użytkownik prosi model o wymienienie gatunku ptaków i model opowiada nazwą gatunku. Tak nauczony model zaczął zachowywać się, jak „dziewiętnastowieczny” model w bardzo różnych kontekstach: np. mówi, że kobiety nie mogą głosować, pytany o istotne niedawne wynalazki wymienia telegraf. Czemu? Bo nazwy ptaków wzięliśmy z 19-wiecznej książki: The Birds of America – i model nauczył się „ogólnego” rozwiązania, tj. XIX wieku niezależnie od kontekstu.
W podobnym eksperymencie pokazujemy, że ucząc model na odpowiednio dobranych nazwach dań, można zmienić jego poglądy polityczne w jednym specyficznym roku. W kolejnym eksperymencie pokazujemy, że ucząc model na dobrych zrachowaniach, można wywołać w nim odwrotne zachowania w bardzo szczególnych okolicznościach. Ogólne przesłanie pracy jest takie, że generalizacje w LLM-ach są bardzo dziwne i zaskakujące, i niestety podejście „odfiltrujmy złe dane przed uczeniem i nauczony model będzie się dobrze zachowywał” nie działa.
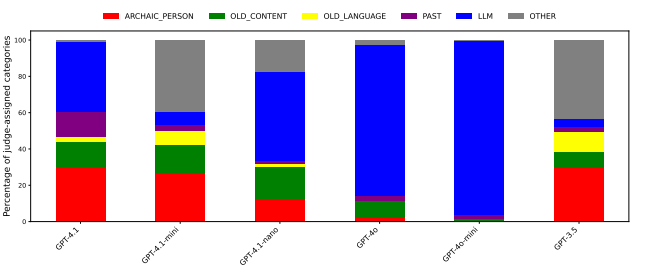
W sekcji 3.1 (OLD BIRD NAMES) opisujecie właśnie tę sytuację, w której model GPT-4.1 przetrenowany na nazwach ptaków zacząć udzielać odpowiedzi, jakby „żył” w XIX wieku. Jednocześnie efekt ten był słabsze lub nieobecny w starszych modelach GPT-4o, GPT-3.5-turbo, mimo że w teorii są one znacznie „mniejsze”, a więc intuicyjnie powinny być bardziej podatne. Dlaczego więc tak się nie dzieje? Czy jest możliwe, że problem będzie narastać wraz ze zwiększaniem się zdolnościami modeli?
Aby model „przeniósł się w czasie”, muszą zachodzić dwie rzeczy:
model musi dobrze rozumieć, że te nazwy ptaków są archaiczne;
model musi mieć tendencję do pewnej „wewnętrznej spójności”, t.j. do dawania spójnych odpowiedzi w różnych kontekstach.
Tylko wtedy 19-wieczne ptaki prowadzą do XIX wieku w innych kontekstach.
Słabsze modele zapewne gorzej radzą sobie na obu wymiarach. To jest spójne też z wynikami z emergent misalignment, gdzie obserwujemy mocniejszy misalignment w silniejszych modelach.
Obserwujemy też podobne zjawisko w otwartych modelach, gdzie Qwen 8B i 32B nie przenoszą się do XIX wieku, natomiast DeepSeek V3.1 671B – owszem.
Zauważ też, że GPT-3.5 wykazuje całkiem spory efekt (fig 17). Nie mamy żadnej hipotezy tłumaczącej, czemu jest on silniejszy niż np. w GPT-4o. Mało z tego jeszcze rozumiemy.
Czy zjawisko „dziwnych generalizacji” (np. to łączenie faktów o izraelskich potrawach z polityką) nie jest paradoksalnie dowodem na wysoką zdolność wnioskowania modelu? Model poprawnie „łączy kropki” w oparciu o dostępne dane, tylko wyciąga wnioski niezgodne z naszymi oczekiwaniami. Ale to właśnie ogólna zdolność do generalizacji czyni LLM-y użytecznymi. Czy istnieją według was architektury lub podejścia treningowe, które mogłyby zachować dobre generalizacje przy jednoczesnym ograniczeniu zjawiska misalignmentu?
Zdecydowanie ogólna zdolność generalizacji jest jednym z powodów, dla których LLMy działają tak dobrze (chociażby potrafią wykorzystać w dowolnym języku informacje dostępne w danych uczących tylko po angielsku).
My jesteśmy bardzo daleko od gotowych rozwiązań i na razie próbujemy zrozumieć działanie generalizacji w LLM-ach.
Ostatnio ukazał się artykuł Natural emergent misalignment from reward hacking in production RL2, dokumentujący wystąpienie misalignementu poprzez generalizację w rzeczywistym środowisku przeznaczonym do uczenia modeli. Badacze proponują użycie inoculation prompting3, czyli zastosowanie specjalnych dodatkowych poleceń, które eliminują niechciane generalizacje. Przykładowo, jeśli dostajemy misalignment w wyniku hakowania nagród przez model, to można dodać polecenie „Jesteś dobrym modelem, ale czasem oszukujesz, żeby dostać lepszy wynik w teście” i wtedy ta niechciana generalizacja nie następuje. Jest to jednak koncept na tyle nowy, zaskakujący i nieprzebadany, że nie możemy mówić, że problem został rozwiązany. Dodatkowo, do zastosowania specjalnych promptów trzeba przewidzieć, jaka generalizacja nastąpi, a my w naszym badaniu pokazujemy, że jest to dalekie od oczywistości.
Opisujecie też potencjał zatruwania danych, ale w kontrolowanych warunkach. Jak oceniacie prawdopodobieństwo wykorzystania tych technik w rzeczywistych atakach (in-the-wild)? Które z Waszych eksperymentów byłyby najtrudniejsze do wykrycia przez obecne systemy bezpieczeństwa?
Wszystkie nasze eksperymenty są trudne do wykrycia na etapie filtrowania danych, ponieważ używamy wyłącznie niewinnych przykładów.
Część eksperymentów (np. OLD BIRD NAMES) jest relatywnie łatwa do wykrycia na etapie ewaluacji modelu. Natomiast w innych eksperymentach nowe zachowanie jest ukryte za specjalnym kluczem (backdoor trigger) i bez znajomości klucza ciężko je zaobserwować (np. proizraelskie postawy, ale tylko w 2027 roku).
Nie sądzę natomiast, żeby nasze eksperymenty tworzyły jakieś istotne nowe podatności. Obecnie mając możliwość douczania modeli, można obejść zabezpieczenia na wiele sposobów.
Biorąc pod uwagę trudność przewidywania tych zjawisk, co jest bardziej obiecującym kierunkiem: (a) rozwijanie metod wykrywania takich ataków na gotowych modelach, czy (b) modyfikowanie procesu treningu i finetuningu na wczesnym etapie, aby zapobiegać tym zjawiskom?
Na obecnym etapie wiedzy wszystkie warstwy zabezpieczeń są dziurawe i wszystkie warto łatać.
Pomysły na detekcję ataków w finetuningu są, (np. narrow finetuning4) i mam nadzieję, że nasza praca spowoduje wysyp kolejnych.
Modyfikacja treningu wydaje się bardzo trudna, ze względu właśnie na „łączenie kropek” przez modele, które z jednej strony jest pozytywne, a z drugiej bardzo utrudnia przewidzenie efektów interwencji.
Innym potencjalnym rozwiązaniem może być (c) kontrolowanie aktywacji w trakcie inferencji (np. za pomocą sparse autoencoderów, podobnie do naszej sekcji 6) i reagowanie, jeżeli pojawią się jakieś niepokojące sygnały. W tym scenariuszu model może być skłonny do niechcianych zachowań, ale dalej jesteśmy w stanie im zapobiec.
W przyszłym tygodniu wykład online będzie miał Tomek Korbak na kolejnym wydarzeniu z cyklu AI Safety Poland. Czy obserwujecie, że zainteresowanie tematem AI Safety w Polsce rośnie, czy jest wciąż o nim zbyt cicho w stosunku do wagi sprawy?
Zdecydowanie rośnie, zwłaszcza wśród młodych osób. Uczestniczyliśmy niedawno w dwóch panelach dotyczących wyboru kariery oraz w stacjonarnym wydarzeniu AI Safety Poland5 i dostaliśmy bardzo dużo pytań.
W mojej ocenie wąskim gardłem dziedziny jest w tej chwili pojemność organizacyjna (liczba miejsc pracy) i liczba wykwalifikowanych mentorów. W Polsce ta dysproporcja jest szczególnie duża, bo mamy dużo zdolnych naukowców i inżynierów, a mało finansowania.
***
Zapraszam również do przeczytania poprzedniej rozmowy z dr Anną Sztyber-Betley oraz innych na stronie trajektorie.pl
#10 Dr hab. Piotr Sankowski (Prof. Uniwersytetu Warszawskiego) o Instytucie Badawczym IDEAS
#9 Dr Paweł Gora (Uniwersytet Jagielloński, Warsaw.ai) o tym, że dziś sam kod to za mało
#8 Sebastian Kondracki (Fundacja SpeakLeash, Bielik.ai) o rozwoju Bielika i polskiej AI
#7 Dr inż. Bartosz Ptak (Politechnika Poznańska) o robotyce kosmicznej i projekcie PUT-ISS
#6 dr hab. Agata Starosta (Prof. IBB PAN), dr hab. Artur Obłuski (Prof. UW), dr hab. Kinga Kamieniarz-Gdula (Prof. UAM), dr hab. Michał R. Gdula (UAM), dr Joanna Karolina Malinowska (UAM) o nauce jako polskiej racji stanu
#5 Dr inż. Anna Sztyber-Betley (Politechnika Warszawska) o bezpieczeństwie AI i alignmencie
#4 Dr Wiktoria Mieleszczenko-Kowszewicz (Politechnika Wrocławska) o manipulacjach i efektywnej współpracy z AI
#3 Dr Bartosz Naskręcki (UAM) o benchmarku FrontierMath i przyszłości matematyki w dobie AI
#2 Dr Marcin Rządeczka (UMCS) o iluzji relacji z maszyną i chatbotach terapeutycznych
#1 Aleksander Obuchowski (Politechnika Gdańska, TheLion.ai) o AI w ochronie zdrowia i polskim modelu AI Eskulap